RabbitMQ分布式集群架构和高可用性(HA)
(一) 功能和原理
设计集群的目的
- 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
- 通过增加更多的节点来扩展消息通信的吞吐量
1 集群配置方式
RabbitMQ可以通过三种方法来部署分布式集群系统,分别是:cluster,federation,shovel
cluster:
- 不支持跨网段,用于同一个网段内的局域网
- 可以随意的动态增加或者减少
- 节点之间需要运行相同版本的RabbitMQ和Erlang
federation:应用于广域网,允许单台服务器上的交换机或队列接收发布到另一台服务器上交换机或队列的消息,可以是单独机器或集群。federation队列类似于单向点对点连接,消息会在联盟队列之间转发任意次,直到被消费者接受。通常使用federation来连接internet上的中间服务器,用作订阅分发消息或工作队列。
shovel:连接方式与federation的连接方式类似,但它工作在更低层次。可以应用于广域网。
2 节点类型
RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和vhost的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息。
问题说明: RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
3 Erlang Cookie
Erlang Cookie是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
说明: 这就要从rabbitmqctl命令的工作原理说起,RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证。
4 镜像队列
功能和原理 RabbitMQ的Cluster集群模式一般分为两种,普通模式和镜像模式。
- 普通模式:默认的集群模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
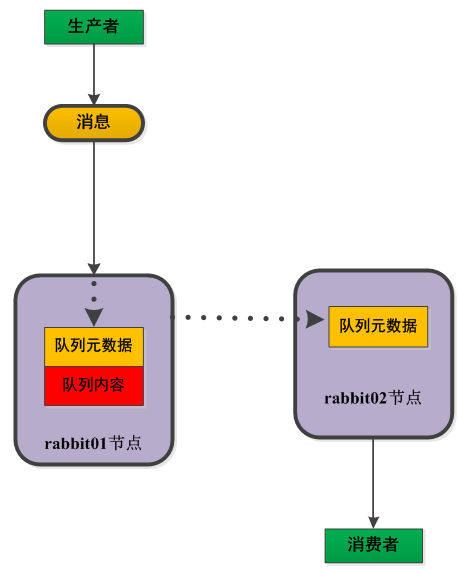
下面表示在集群配置下的不同节点创建队列的情况
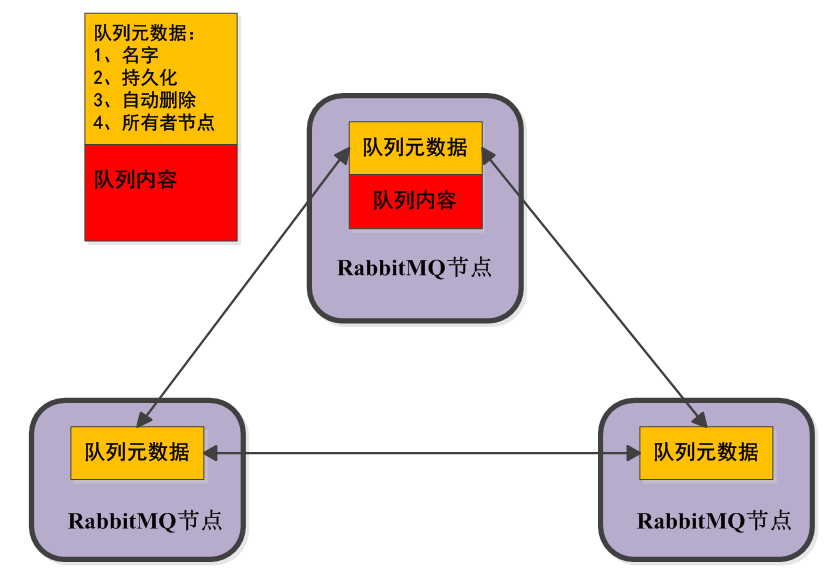
下图表示在集群配置下的不同节点创建交换器和队列的绑定的情况
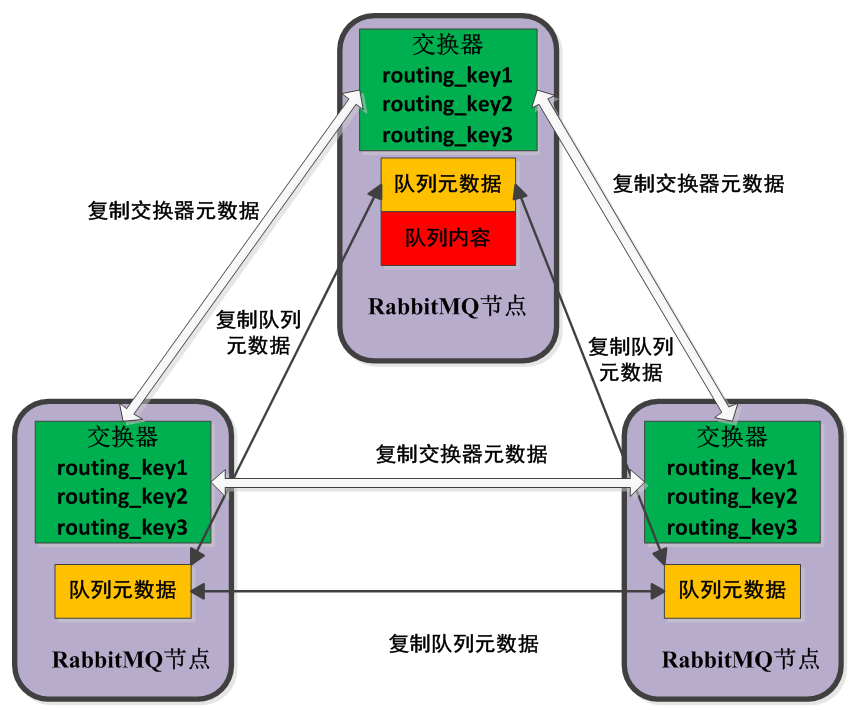
- 镜像模式:将需要消费的队列变为镜像队列,存在于多个节点,这样就可以实现RabbitMQ的HA高可用性。作用就是消息实体会主动在镜像节点之间实现同步,而不是像普通模式那样,在consumer消费数据时临时读取。缺点就是,集群内部的同步通讯会占用大量的网络带宽。
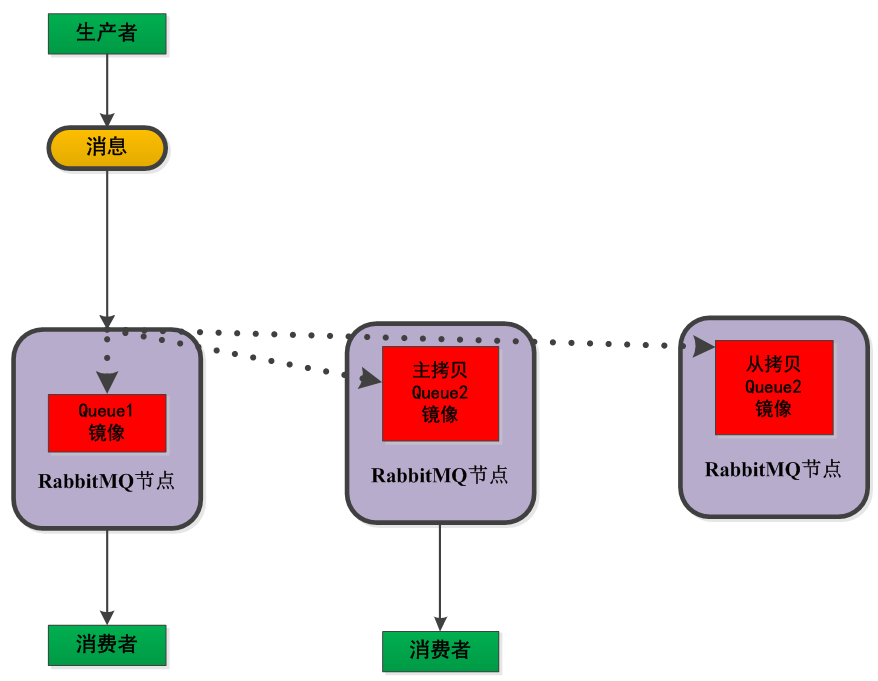
实现机制 镜像队列实现了RabbitMQ的高可用性(HA),具体的实现策略如下所示:
| ha-mode | ha-params | 功能 |
|---|---|---|
| all | 空 | 镜像队列将会在整个集群中复制。当一个新的节点加入后,也会在这 个节点上复制一份。 |
| exactly | count | 镜像队列将会在集群上复制count份。如果集群数量少于count时候,队列会复制到所有节点上。如果大于Count集群,有一个节点crash后,新进入节点也不会做新的镜像。 |
| nodes | node name | 镜像队列会在node name中复制。如果这个名称不是集群中的一个,这不会触发错误。如果在这个node list中没有一个节点在线,那么这个queue会被声明在client连接的节点。 |
实例列举:
1 2 | |
如果需要设定特定的节点(以rabbit@localhost为例),再添加一个参数
1 2 3 | |
可以通过命令行查看那个主节点进行了同步
1
| |
(二) RabbitMQ Cluster 配置
1 单机多节点部署
在启动RabbitMQ节点之后,服务器默认的节点名称是Rabbit和监听端口5672,如果想在同一台机器上启动多个节点,那么其他的节点就会因为节点名称和端口与默认的冲突而导致启动失败,可以通过设置环境变量来实现,具体方法如下:
- 首先在机器上设置两个节点rabbit和rabbit_01
1 2 3 4 5 | |
或者通过添加/etc/rabbitmq/rabbitmq-env.conf文件来进行设置:
1 2 3 4 | |
- 将rabbit_01节点添加到第一个集群节点rabbit中
1 2 3 4 | |
1 2 3 4 5 6 7 | |
2 多机多节点部署
不同于单机多节点的情况,在多机环境,如果要在cluster集群内部署多个节点,需要注意两个方面:
- 保证需要部署的这几个节点在同一个局域网内
- 需要有相同的Erlang Cookie,否则不能进行通信,为保证cookie的完全一致,采用从一个节点copy的方式
环境介绍:
| RabbitMQ节点 | IP地址 | 工作模式 | 操作系统 |
|---|---|---|---|
| rabbitmqCluster | 192.168.118.133 | DISK | CentOS 7.0 - 64位 |
| rabbitmqCluster01 | 192.168.118.134 | DISK | CentOS 7.0 - 64位 |
| rabbitmqCluster02 | 192.168.118.135 | DISK | CentOS 7.0 - 64位 |
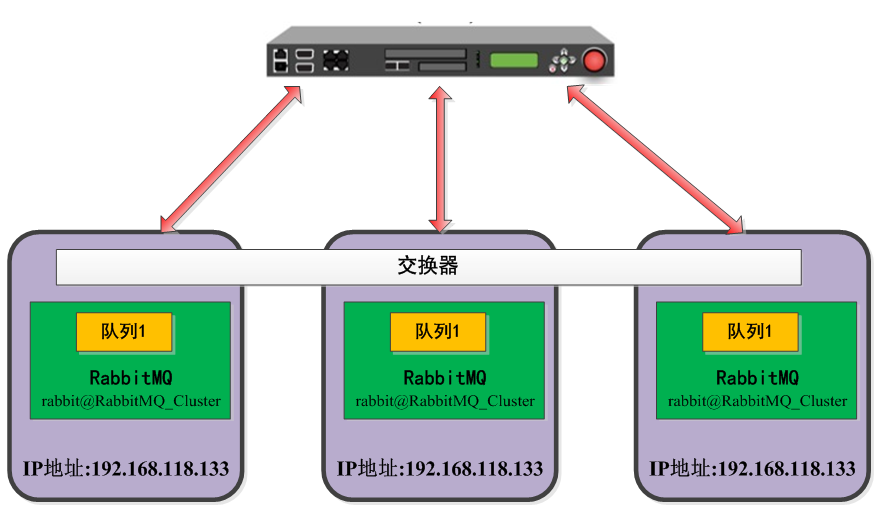
cluster部署过程:
- 局域网配置 分别在三个节点的/etc/hosts下设置相同的配置信息
1 2 3 | |
- 设置不同节点间同一认证的Erlang Cookie 采用从主节点copy的方式保持Cookie的一致性
1 2 | |
- 使用 -detached运行各节点
1 2 | |
- 查看各节点的状态
1 2 3 | |
- 创建并部署集群,以rabbitmqCluster01节点为例:
1 2 3 | |
- 查看集群状态
1
| |
RabbitMQ负载均衡配置
前言:从目前来看,基于RabbitMQ的分布式通信框架主要包括两部分内容,一是要确保可用性和性能,另一个就是编写当节点发生故障时知道如何重连到集群的应用程序。负载均衡就是解决处理节点的选择问题。
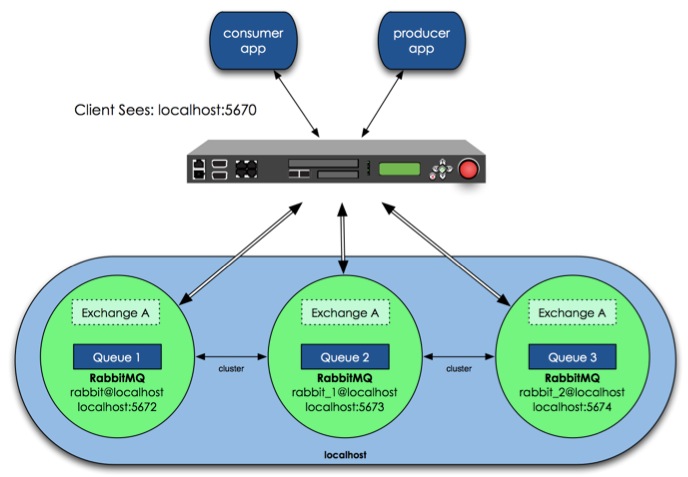
安装HAProxy
选择开源的HAProxy为RabbitMQ集群做负载均衡器,在CentOS 7.0中安装HAProxy。
- 安装epel
1
| |
- 安装HAProxy
1
| |
- 配置HAProxy
1 2 | |
- 添加配置信息
1 2 3 4 5 6 7 8 9 10 11 | |
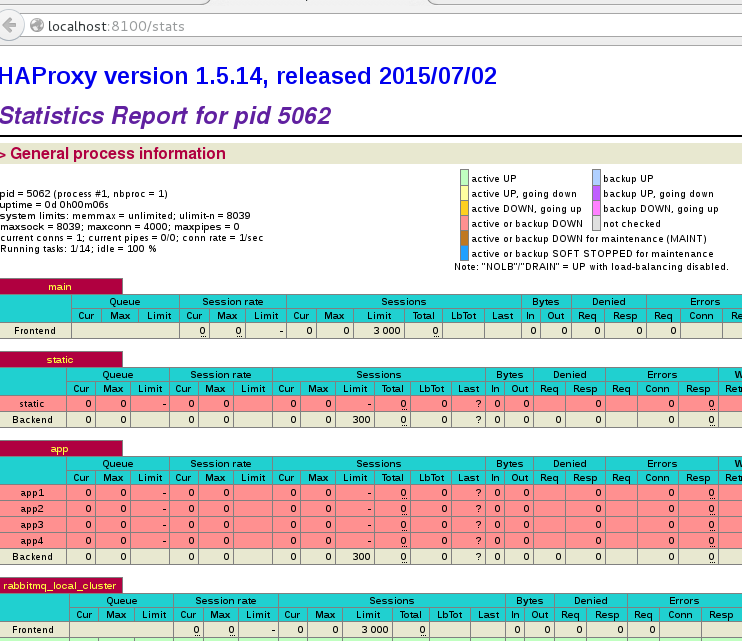
- 设置开机启动
1 2 | |
- 访问localhost:8100/stats就可以看到具体的控制界面。