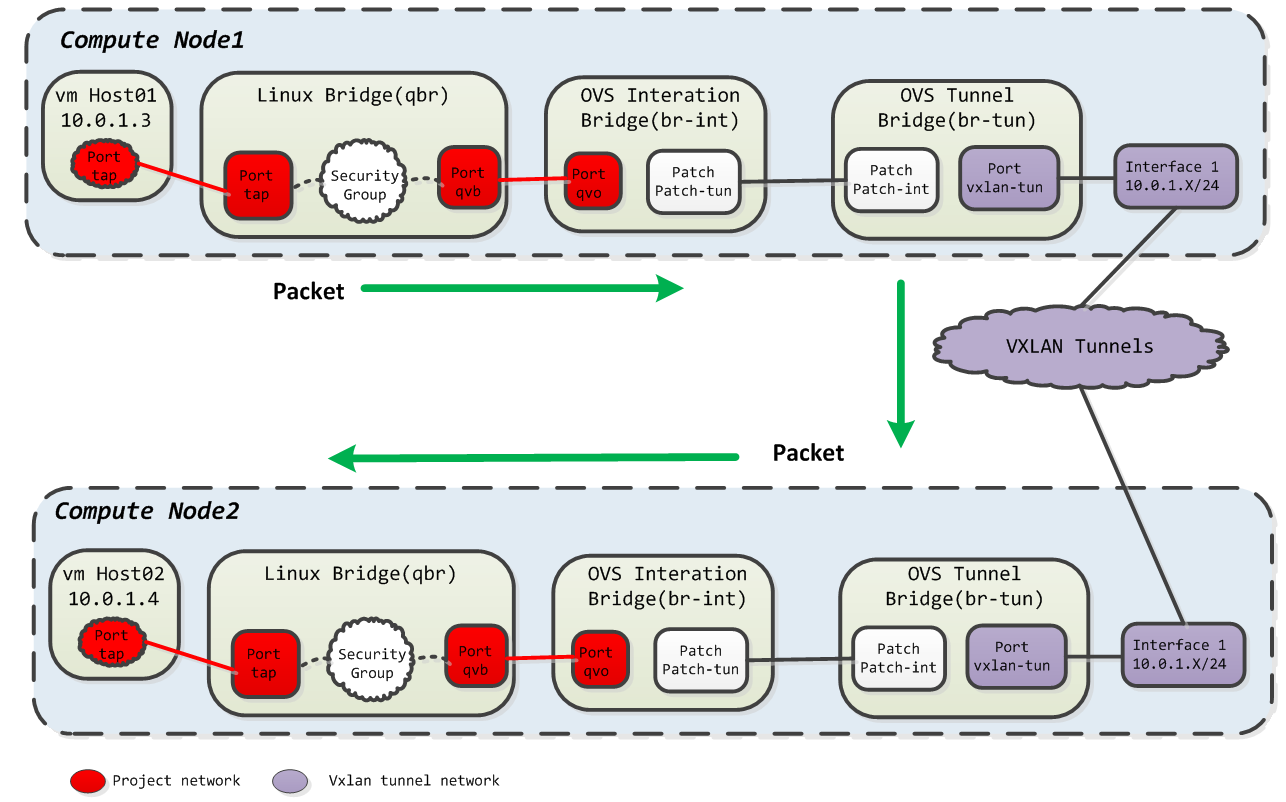
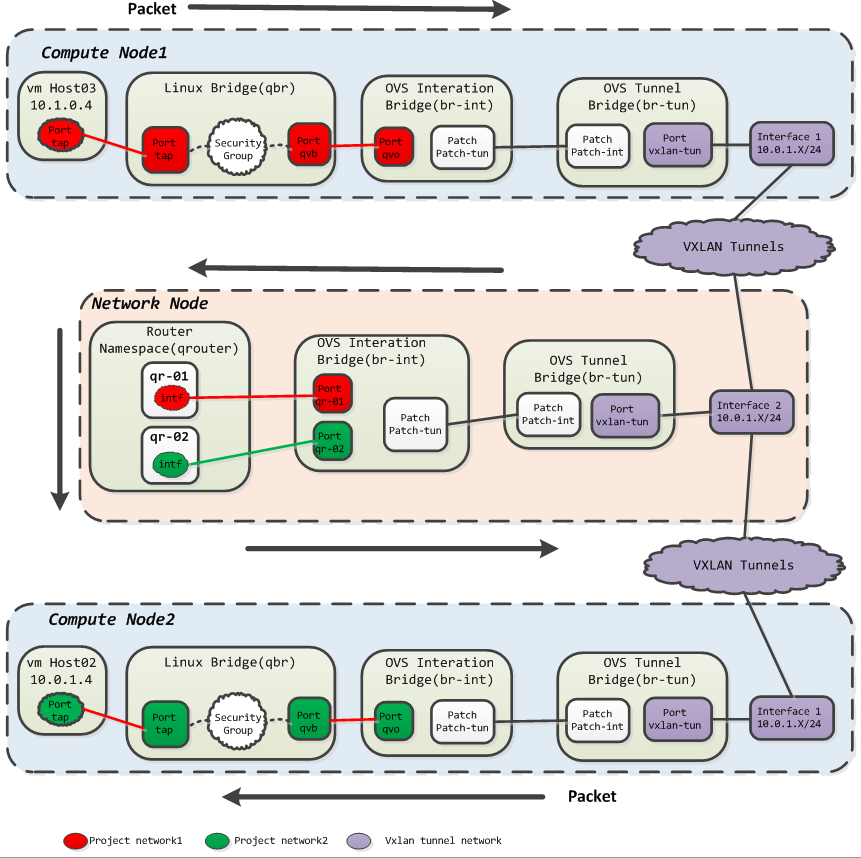
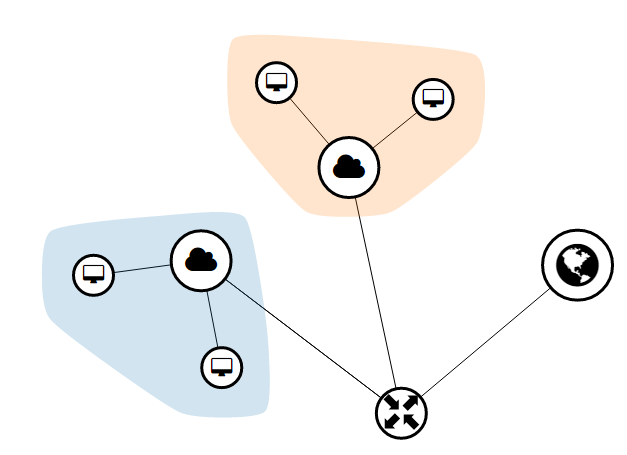
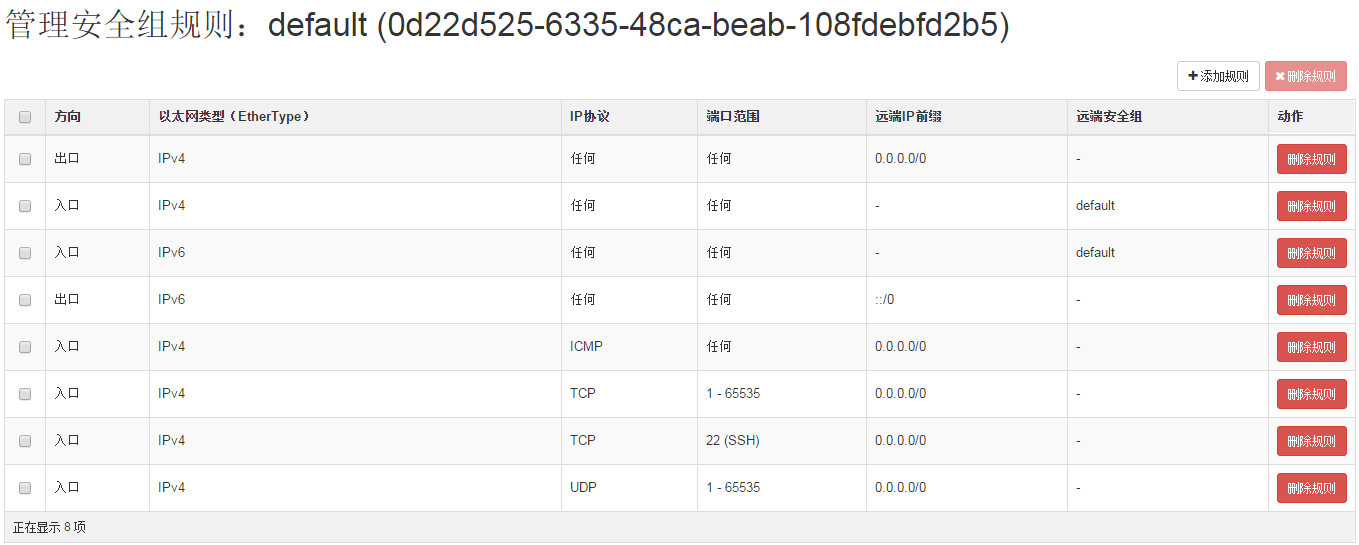
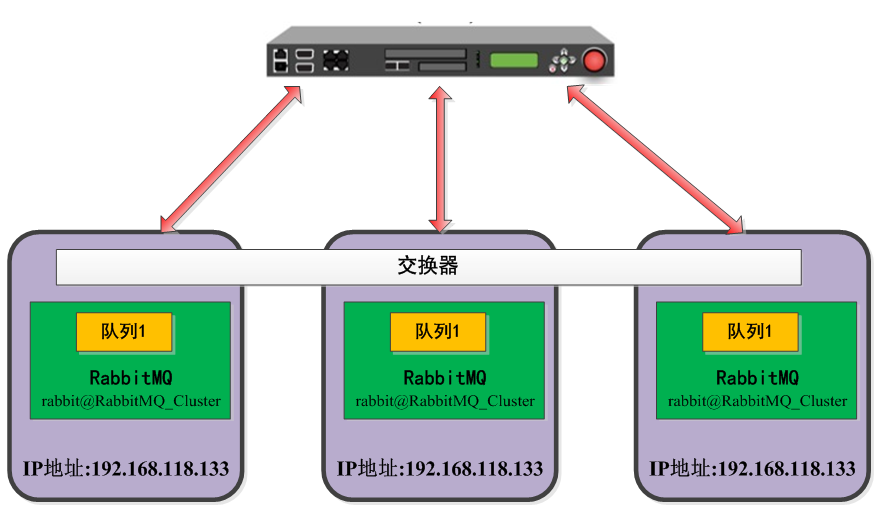
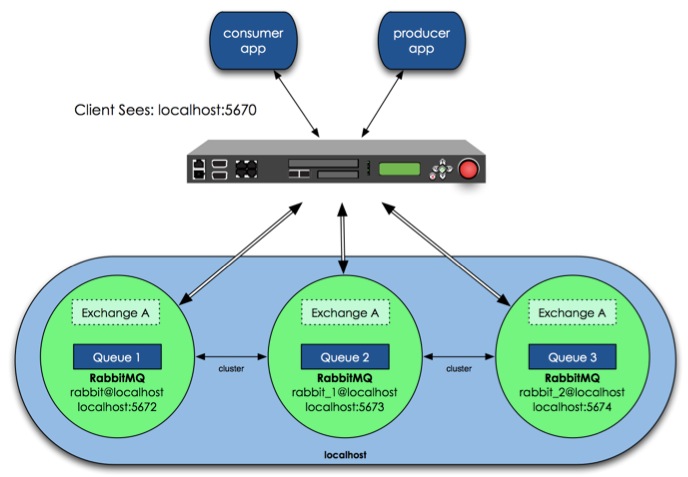
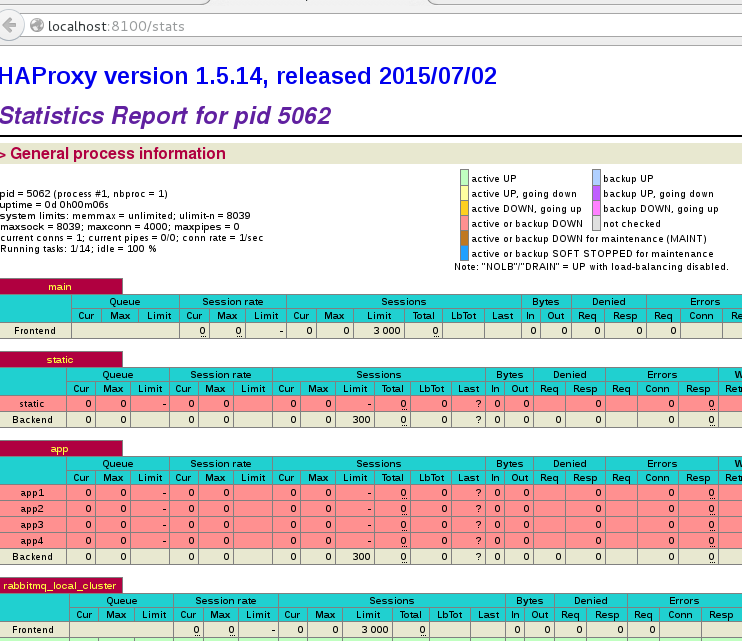
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| [root@host41 ~]# ovs-ofctl dump-flows br-tun
NXST_FLOW reply (xid=0x4):
cookie=0xa08ff20bf20b5fae, duration=1640812.296s, table=0, n_packets=557112, n_bytes=280383648, idle_age=20, hard_age=65534, priority=1,in_port=1 actions=resubmit(,2)
cookie=0xa08ff20bf20b5fae, duration=1204517.666s, table=0, n_packets=14004, n_bytes=1142528, idle_age=8775, hard_age=65534, priority=1,in_port=2 actions=resubmit(,4)
cookie=0xa08ff20bf20b5fae, duration=1204499.592s, table=0, n_packets=502898, n_bytes=59684255, idle_age=20, hard_age=65534, priority=1,in_port=3 actions=resubmit(,4)
cookie=0xa08ff20bf20b5fae, duration=1204494.411s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,in_port=4 actions=resubmit(,4)
cookie=0xa08ff20bf20b5fae, duration=1640812.286s, table=0, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=drop
cookie=0xa08ff20bf20b5fae, duration=1640812.282s, table=2, n_packets=552989, n_bytes=280198986, idle_age=20, hard_age=65534, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)
cookie=0xa08ff20bf20b5fae, duration=1640812.282s, table=2, n_packets=4123, n_bytes=184662, idle_age=19451, hard_age=65534, priority=0,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,22)
cookie=0xa08ff20bf20b5fae, duration=1640812.282s, table=3, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=drop
cookie=0xa08ff20bf20b5fae, duration=1640748.151s, table=4, n_packets=747602, n_bytes=98745467, idle_age=20, hard_age=65534, priority=1,tun_id=0x10059 actions=mod_vlan_vid:1,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640748.106s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,tun_id=0x10052 actions=mod_vlan_vid:2,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640748.081s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,tun_id=0x1005d actions=mod_vlan_vid:3,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640748.055s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,tun_id=0x1000c actions=mod_vlan_vid:4,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640748.007s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,tun_id=0x1001d actions=mod_vlan_vid:5,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640747.977s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=1,tun_id=0x10068 actions=mod_vlan_vid:6,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1213356.221s, table=4, n_packets=937, n_bytes=99354, idle_age=27478, hard_age=65534, priority=1,tun_id=0x1003a actions=mod_vlan_vid:8,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=95292.240s, table=4, n_packets=119, n_bytes=10570, idle_age=8748, hard_age=65534, priority=1,tun_id=0x10049 actions=mod_vlan_vid:14,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=95266.306s, table=4, n_packets=106, n_bytes=8850, idle_age=18993, hard_age=65534, priority=1,tun_id=0x1003d actions=mod_vlan_vid:15,resubmit(,10)
cookie=0xa08ff20bf20b5fae, duration=1640812.281s, table=4, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=drop
cookie=0xa08ff20bf20b5fae, duration=1640812.281s, table=6, n_packets=0, n_bytes=0, idle_age=65534, hard_age=65534, priority=0 actions=drop
cookie=0xa08ff20bf20b5fae, duration=1640812.281s, table=10, n_packets=764906, n_bytes=100191850, idle_age=20, hard_age=65534, priority=1 actions=learn(table=20,hard_timeout=300,priority=1,cookie=0xa08ff20bf20b5fae,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:1
cookie=0xa08ff20bf20b5fae, duration=1883.824s, table=20, n_packets=551, n_bytes=252408, hard_timeout=300, idle_age=20, hard_age=19, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:b4:00:8c actions=load:0->NXM_OF_VLAN_TCI[],load:0x10059->NXM_NX_TUN_ID[],output:3
cookie=0xa08ff20bf20b5fae, duration=1640812.281s, table=20, n_packets=1968, n_bytes=161462, idle_age=2375, hard_age=65534, priority=0 actions=resubmit(,22)
cookie=0xa08ff20bf20b5fae, duration=1213356.228s, table=22, n_packets=9, n_bytes=378, idle_age=65534, hard_age=65534, dl_vlan=8 actions=strip_vlan,set_tunnel:0x1003a,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.358s, table=22, n_packets=30, n_bytes=1316, idle_age=65534, hard_age=65534, dl_vlan=2 actions=strip_vlan,set_tunnel:0x10052,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.351s, table=22, n_packets=15, n_bytes=686, idle_age=65534, hard_age=65534, dl_vlan=3 actions=strip_vlan,set_tunnel:0x1005d,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.344s, table=22, n_packets=2, n_bytes=140, idle_age=65534, hard_age=65534, dl_vlan=4 actions=strip_vlan,set_tunnel:0x1000c,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.337s, table=22, n_packets=3186, n_bytes=161198, idle_age=2375, hard_age=65534, dl_vlan=1 actions=strip_vlan,set_tunnel:0x10059,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.331s, table=22, n_packets=15, n_bytes=686, idle_age=65534, hard_age=65534, dl_vlan=5 actions=strip_vlan,set_tunnel:0x1001d,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640746.324s, table=22, n_packets=2, n_bytes=140, idle_age=65534, hard_age=65534, dl_vlan=6 actions=strip_vlan,set_tunnel:0x10068,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=95292.249s, table=22, n_packets=16, n_bytes=1208, idle_age=65534, hard_age=65534, dl_vlan=14 actions=strip_vlan,set_tunnel:0x10049,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=95266.313s, table=22, n_packets=30, n_bytes=2200, idle_age=18999, hard_age=65534, dl_vlan=15 actions=strip_vlan,set_tunnel:0x1003d,output:3,output:2,output:4
cookie=0xa08ff20bf20b5fae, duration=1640812.267s, table=22, n_packets=173, n_bytes=14398, idle_age=65534, hard_age=65534, priority=0 actions=drop
|